# 语音识别_v1.1
语音识别接口定义了语音输入相关功能,如果需要使用语音交互能力,客户端必须实现此接口,接口包含了上传语音,服务端下发开始接听和停止收听指令。
# 版本修改
| 版本 | 新增 |
|---|---|
| v1.1 | Recognize指令的payload增加iFLYOS.Score字段 |
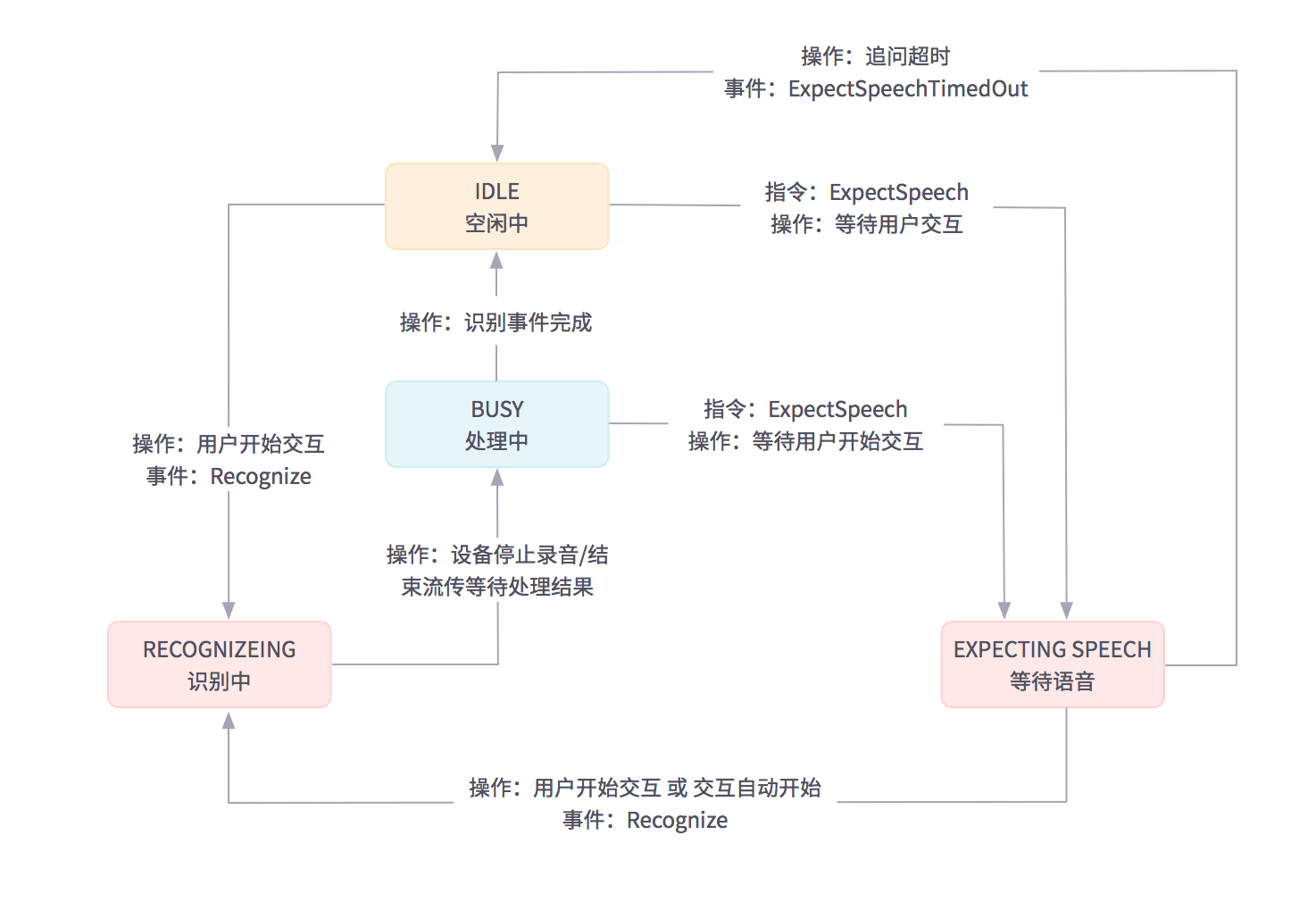
# 状态
IDLE(空闲状态): 在接收用户语音之前,云端语音交互正常完成后,或发生语音识别超时后,语音识别控件应该是空闲状态。另外,在多轮会话中接收完用户语音后,语音识别控件也需要回到空闲状态。
RECOGNIZING(识别): 当用户开始和设备端交互,语音开始流传至云端时,语音识别控件需要从空闲状态转换为识别状态。识别状态需要一直保持到设备端停止录音(或语音流传完成)。
BUSY(处理中): 正在处理语音请求时,语音识别控件应该是繁忙状态。在繁忙状态设备端不能开始另一个语音请求。若语音请求完成,则语音识别控件从繁忙状态变为空闲状态;若云端需要用户更多的语音输入,则语音识别控件从繁忙状态变为等待语音状态。
EXPECTING SPEECH(等待语音): 当云端需要用户更多的语音输入时,语音识别控件必须是等待语音状态。当用户开始说话或交互自动开始时,语音识别控件从等待语音状态转换为识别状态;若在超时时间内用户没有语音输入,语音识别控件从等待语音状态变为空闲状态。
# Recognize 事件
当用户发起语音请求的时候(唤醒,触屏等),设备需要上报Recognize事件,并把请求的语音附带上传,云端在接收到Recognize事件之后,经过一系列的处理,最终下发对应的指令给客户端执行,完成一轮语音交互。
该事件由多个部分组成:第一部分是一个JSON对象,第二部分是一个麦克风捕捉的音频数据。
在一个语音交互开始之后,麦克风需要一直开启直到:
- 接收到
StopCapture指令 - 语音流被云端结束
- 用户手工关闭了麦克风,场景:长按录音松开结束录音。
profile参数和initiator对象将告诉云端应该使用哪一个语音识别引擎以获得最好的语义理解效果。
# 消息样式
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "Recognize",
"messageId": "e52e7a4c...",
"dialogRequestId": "49687be..."
},
"payload": {
"profile": "String",
"format": "String",
"initiator": {
"type": "String",
"payload": {
"wakeWordIndices": {
"startIndexInSamples": 50,
"endIndexInSamples": 150
},
"iFLYOS.Score": 666,
"token": "S0wiXQZ1rVBkov..."
}
}
}
}
}
# 音频编码
iFLYOS 支持识别 16-bit 位深度、16000Hz 采样率、单声道的音频。具体支持的编码如下:
| format | 说明 | 建议块大小 |
|---|---|---|
| AUDIO_L16_RATE_16000_CHANNELS_1 | PCM,Little-Endian | 640字节 |
| OPUS | OPUS 压缩,32000bps 固定比特率 (CBR),VOIP 模式 | 96字节 |
| SPEEX_WB_QUALITY_9 | SPEEX 压缩,宽带 (wideband),Quality 9 | 86字节 |
为了减少网络延迟带来的影响,我们建议按照上表中建议的大小分块(chunk),通过流传方式上传音频数据。
# 二进制附件
每一个Recognize事件都跟随着一个二进制的part携带录音数据:
Content-Disposition: form-data; name="audio"
Content-Type: application/octet-stream
{{BINARY AUDIO ATTACHMENT}}
# header 参数
| 参数名 | 说明 | 类型 |
|---|---|---|
| messageId | 代表一条message的唯一ID | String |
| dialogRequestId | 客户端必须为recognize请求创建的唯一ID,此参数用于关联响应特定Recognize事件发送的指令 | String |
# Payload 参数
| 参数名 | 说明 | 类型 | 必须出现 |
|---|---|---|---|
| profile | iFLYOS支持三种识别引擎,你可以根据的需要选择。 取值: CLOSE_TALK:监听距离0-0.5米; NEAR_FIELD:监听距离:0-1.5米; FAR_FIELD:监听距离:0-10米 | String | 是 |
| format | 音频编码,见上文 | String | 是 |
| initiator | 让云端知道语音交互是怎么开始的,如唤醒词、点击、长按。 当接收 ExpectSpeech指令时,若指令中包含initiator参数,在接下来的recognize时间中该参数值必须返回;若指令中没有包含该参数,在该事件中不应该有此参数。 | Object | 是 |
| initiator.type | 开始语音交互的方式 取值: PRESS_AND_HOLD:长按 TAP:点击 WAKEWORD:唤醒词 | String | 是 |
| initiator.payload | 包含initiator的信息 | Object | 是 |
| initiator.payload. wakeWordIndices | 当initiator.type的值为WAKEWORD时,该参数必填。参数中包含startIndexInSamples和endIndexInSamples | String | 否 |
| initiator.payload. wakeWordIndices. startIndexInSamples | 代表音频流中唤醒词开始的位置,这个数值应该精确到唤醒词出现的50毫秒内 | Long | 否 |
| initiator.payload. wakeWordIndices. endIndexInSamples | 代表音频流中唤醒词结束的位置,这个数值应该精确到唤醒词结束的150毫秒内 | Long | 否 |
| initiator.payload. iFLYOS.Score | 当initiator.type的值为WAKEWORD时,该参数必填。 | int | 否 |
| initiator.payload.token | token参数只有在响应ExpectSpeech指令时出现 | String | 否 |
initiator.type 的取值
| initiator取值 | 描述 | 适合的profile | StopCapture指令 | wakeWordIndices参数出现 |
|---|---|---|---|---|
| PRESS_AND_HOLD | 长按录音,松开停止录音 | CLOSE_TALK | N | N |
| TAP | 点击录音,接收指令停止录音 | NEAR_FIELD, FAR_FIELD | Y | N |
| WAKEWORD | 唤醒词录音,接收指令停止录音 | NEAR_FIELD, FAR_FIELD | Y | Y |
# StopCapture 指令
一般情况下,我们在上传音频的时候使用的是流传,当服务端识别出用户意图,或用户语音结束时,设备端会收到该指令。所以当接收到 StopCapture 指令的时候,你应该立即停止接收语音,并关闭麦克风,将设备切换到未唤醒状态。该指令通过下行通道下发,此时设备可能还在上传音频流,所以只有在你的profile参数取值为NEAR_FIELD或FAR_FIELD时你才可以接收到该指令。
# 消息样式
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "StopCapture",
"messageId": "e52e7a4c...",
"dialogRequestId": "49687be..."
},
"payload": {}
}
}
# header 参数
| 参数名 | 说明 | 类型 |
|---|---|---|
| messageId | 代表一条message的唯一ID | String |
| dialogRequestId | 客户端必须为recognize请求创建的唯一ID,此参数用于关联响应特定Recognize事件发送的指令 | String |
# ExpectSpeech 指令
当服务端需要追问更多信息时将发送ExpectSpeech指令,该指令要求客户端打开麦克风并开始传送用户语音。如果在规定的超时时间内麦克风没有打开,客户端需要上报ExpectSpeechTimedOut 事件到云端。
在多轮会话中,你的设备将接收至少一次ExpectSpeech指令来接收更多用户语音输入。此时,如果指令的payload中包含initiator参数,这个参数值必须在下一次Recognize事件中回传至云端;如果payload中没有该参数,则下一次Recognize事件中不应该包含initiator参数。
# 消息样式
{
"directive": {
"header": {
"namespace": "SpeechRecognizer",
"name": "ExpectSpeech",
"messageId": "e52e7a4c...",
"dialogRequestId": "49687be..."
},
"payload": {
"timeoutInMilliseconds": 60000,
"initiator": {
"type": "String",
"payload": {
"token": "S0wiXQZ1rVBkov..."
}
}
}
}
}
# Header参数
| 参数名 | 说明 | 类型 |
|---|---|---|
| messageId | 代表一条message的唯一ID | String |
| dialogRequestId | 客户端必须为recognize请求创建的唯一ID,此参数用于关联响应特定Recognize事件发送的指令 | String |
# Payload参数
| 参数名 | 说明 | 类型 | 必须出现 |
|---|---|---|---|
| timeoutInMilliseconds | 客户端等待用户说话的毫秒数。如果在规定时间内未打开麦克风,则客户端需要上报ExpectSpeechTimedOut事件至服务端,这种情况主要出现在长按录音的时候 | Long | 是 |
| initiator | 语音交互开始的方式,若指令中包含initiator参数,在接下来的recognize时间中该参数值必须返回 | Object | 否 |
| initiator.type | 开始语音交互的方式,若指令中包含initiator.type参数,在接下来的recognize时间中该参数值必须返回 | String | 否 |
| initiator.payload | intiator的信息 | Object | 否 |
| initiator.payload.token | 一个token,若指令中包含initiator.payload.token参数,在接下来的recognize时间中该参数值必须返回 | String | 否 |
# ExpectSpeechTimedOut事件
当接收到ExpectSpeech指令,但在规定的超时时间内无法响应(麦克风未打开)时,设备必须上报该事件到云端。
# 消息样式
{
"event": {
"header": {
"namespace": "SpeechRecognizer",
"name": "ExpectSpeechTimedOut",
"messageId": "e52e7a4c...",
},
"payload": {
}
}
}
# Header参数
| 参数名 | 说明 | 类型 |
|---|---|---|
| messageId | 代表一条message的唯一ID | String |
# Payload参数
传送空的payload。